Cara Kerja Machine Learning
Pada beberapa bagian sebelumnya kita telah mengenali beberapa algoritma machine learning. Agar lebih memahaminya sebaiknya kita mengetahui bagaimana cara kerja machine learning itu. Machine learning pada awalnya bekerja dengan cara belajar yang bertujuan untuk menghasilkan model tertentu. Model yang telah dibentuk itu nantinya akan menjadi informasi untuk pemecahan masalah baik dalam proses input maupun output. Kemudian model tersebut dapat memprediksi atau mengelompokkan data pada kedepannya.
Baca juga : Belajar Data Science: Pahami Penggunaan Machine Learning pada Python
Apa Perbedaan Antara Supervised, Unsupervised, dan Reinforcement Learning?
Machine learning adalah bidang studi dimana manusia mencoba memberikan kemampuan kepada mesin untuk belajar dari data secara eksplisit. Mesin inilah yang kita sebut model machine learning dan yang kita gunakan untuk menyelesaikan masalah kita. Ada berbagai bentuk aplikasi machine learning di industri, misalnya: face recognition machine dan email spam detection adalah aplikasi model machine learning.
Mengetahui model machine learning mana yang harus diterapkan dalam setiap use case sangat penting karena tidak semua model dapat diaplikasikan untuk setiap use case. Model yang sesuai akan meningkatkan metrik model kita.
Machine learning adalah bidang yang luas dengan banyak istilah yang digunakan di dalamnya. Untuk memberikan pemahaman yang jelas tentang apa itu algoritma klasifikasi, pertama-tama kita perlu membahas tentang tiga sistem machine learning yang berbeda berdasarkan pengawasan manusia; Supervised, Unsupervised, dan Reinforcement Learning?
Supervised Learning adalah model machine learning yang menggunakan data training dari manusia yang mencakup solusi yang diinginkan. Data training sudah berisi jawaban untuk masalah yang ingin kita selesaikan, dan mesin diharapkan meniru pola pada input data (prediktor) untuk menghasilkan output yang serupa.
Contoh data training untuk Supervised Learning adalah sebagai berikut:
Gambar 1. Data training untuk Supervised Learning
Ada dua typical tasks dari supervised learning; Klasifikasi dan Regresi. Apa perbedaan di antara keduanya? Pada dasarnya, perbedaannya berasal dari hasil prediksi.
Algoritma klasifikasi berfokus pada hasil prediksi diskrit, misalnya, prediksi Churn (keluar atau tidak), Heart Disease (terpengaruh oleh penyakit jantung atau tidak), dll.
Sebaliknya, algoritma regresi berfokus pada hasil prediksi numerik di mana hasilnya tidak terbatas pada kelas tertentu, misalnya: harga rumah, jarak mobil, penggunaan energi, dll.
Python Libraries untuk Machine Learning
Python dengan libraries, modul, dan kerangkanya bisa digunakan untuk membantu kebutuhan machine learning. Hanya saja, Anda perlu menguasai pengaplikasian Python guna mendapatkan manfaatnya dalam machine learning dan data science. Berikut adalah sepuluh rekomendasi Python libraries yang bisa Anda gunakan.
Pandas adalah library Python yang paling dikenal dan banyak digunakan. Paket ini bisa digunakan untuk menganalisis data dengan cepat, realistis, dan serbaguna. Anda dapat memakainya untuk mengombinasikan, mengelompokkan, dan mengklasifikasikan data yang berasal dari berbagai sumber, seperti Excel, SQL databases, CSV, dan sebagainya. Oleh karena itu, Pandas menjadi salah satu paket Python yang wajib dimiliki lantaran performanya yang stabil dan bersifat open source.
Selanjutnya, ada NumPy atau Numerical Python. NumPy adalah aljabar linear yang dikembangkan dalam Python guna memecahkan berbagai permasalahan terkait numerik. Banyak ahli dan pengguna yang memilih paket ini karena NumPy memiliki kemampuan untuk memecahkan permasalahan-permasalahan rumit menyangkut operasional matematika. Selain itu, NumPy juga banyak digunakan untuk menangani berbagai permasalahan lain, seperti gambar, suara, dan operasional biner lainnya.
Matplotlib adalah salah satu Python libraries yang juga sering digunakan. Paket ini dipakai untuk kepentingan visualisasi data yang melibatkan grafik, plot, histogram, dan lain-lain. Visualisasi data diperlukan untuk memahami data secara lebih mendalam sebelum melakukan data-processing dan melatihnya dalam program machine learning. Matplotlib banyak digemari karena memiliki sifat yang open source dan gratis untuk diakses.
Seaborn adalah salah satu paket yang kerap digunakan dalam Python libraries. Paket ini dirancang di atas Matplotlib dan terintegrasi dengan struktur data dari Pandas. Sama halnya dengan Matplotlib, Seaborn digunakan untuk kepentingan visualisasi data agar data mudah dipahami. Dalam machine learning, Seaborn berfungsi membaca dan memahami data-data untuk kemudian dipetakan dalam bentuk grafis statistik, sehingga dapat menghasilkan plot yang informatif.
Berikutnya adalah SciPy sebagai Python libraries yang cukup dikenal. Paket ini terdiri dari beberapa modul untuk memperoleh hasil terbaik, meliputi statistik, integrasi, hingga aljabar linear. Kelebihan dari SciPy adalah operasionalnya yang mudah untuk mengatasi persoalan matematika. Selain itu, paket ini juga berguna untuk digunakan dalam image manipulation.
Python libraries berikutnya yang tidak kalah populer adalah Scikit-learn. Paket ini menjadi salah satu yang legendaris dalam dunia machine learning. Scikit-learn dibuat atas dua Python libraries, yakni NumPy dan SciPy. Dengan demikian, fungsinya tak jauh berbeda dengan kedua libraries pokoknya, yaitu untuk memecahkan berbagai permasalahan numerik. Namun, paket ini juga bisa digunakan untuk keperluan data mining dan analisis data.
Selanjutnya ada Python libraries yang dikembangkan oleh tim Google Brain dari Google, TensorFlow. Paket ini biasa digunakan untuk memecahkan permasalahan matematika dalam berbagai aplikasi artificial intelligence atau AI. Paket ini banyak digunakan oleh berbagai pengembang lantaran mampu menjalankan komputasi dengan melibatkan tensors. Selain itu, perangkat ini juga memungkinkan penerapan komputasi di berbagai perangkat, mulai dari komputer hingga smartphone.
Keras adalah salah satu Python libraries yang cukup populer. Sebab, paket ini memudahkan para pemula untuk pembuatan prototipe. Selain itu, proses prototyping juga bisa dikatakan jadi lebih cepat. Keras dibuat atas dasar TensorFlow, CNTK, dan Theano. Kelebihan lain dari paket ini adalah mampu digunakan untuk visualisasi data selain menyusun model, mengolah dataset, dan mengevaluasi hasil akhir.
Machine learning pada dasarnya berkutat pada persoalan matematika dan statistik. Begitu juga dengan Theano yang berfungsi untuk mendefinisikan, mengevaluasi, dan mengoptimalkan berbagai himpunan multidimensi dalam matematika. Paket ini biasanya digunakan untuk program komputasi berskala besar. Namun, tidak sedikit juga yang menggunakannya untuk proyek individu.
Terakhir ada PyTorch yang menjadi produk machine learning library dari tim Facebook. Paket ini dibuat untuk menyaingi keberadaan TensorFlow karena keduanya sama-sama menggunakan tensors. Akan tetapi, PyTorch didesain untuk lebih mudah dipahami dan dioperasikan. Meski demikian, paket ini hanya dapat digunakan untuk pengembangan dan pelatihan program deep learning.
Machine learning merupakan pembelajaran mesin yang mempelajari beberapa hal di dalamnya seperti algoritma, ilmu statistik, dan lainnya. Machine learning merupakan teknologi bagian dari Artificial Intelligence. Ketika seseorang melakukan proses pengolahan data, sebagian besar orang membutuhkan algoritma machine learning untuk menyelesaikan atau mencari solusi dari permasalahan data yang ada. Algoritma machine learning pun sangat beragam dan digunakan sesuai dengan masalah data yang sesuai.
Algoritma sendiri merupakan suatu proses langkah demi langkah yang tersusun untuk menyelesaikan permasalahan. Algoritma machine learning sendiri sangat beragam dan sudah sering digunakan untuk menyelesaikan permasalahan data dalam berbagai bidang seperti kesehatan, pendidikan, bisnis, keuangan, dan masih banyak lainnya. Kira-kira apa saja ya algoritma machine learning yang cukup sering digunakan dan bagaimana cara kerja machine learning? Yuk, simak artikel berikut ini!
Naive Bayes merupakan salah satu algoritma supervised learning yang sederhana dan cukup sering digunakan. Algoritma ini menggunakan dasar Teori Bayes di dalamnya. Algoritma ini memiliki data training (data yang sudah terdapat label kelas) dan data testing (data yang belum memiliki label kelas). Algoritma Naive Bayes bekerja dengan cara memaksimalkan nilai suatu kelas. Kelas yang memiliki probabilitas tertinggi akan masuk ke dalam salah satu dari label-label yang tersedia.
Baca juga : 3 Jenis Algoritma Machine Learning yang Dapat Digunakan di Dunia Perbankan
Jika pada algoritma supervised learning salah satu tujuan kita adalah untuk mengetahui label kelas pada data, maka pada unsupervised learning tidak berlaku demikian. K-Means merupakan salah satu algoritma supervised learning yang mana cara kerjanya adalah mengklaster atau mengelompokkan data sesuai dengan karakteristik atau kemiripan data menjadi beberapa klaster sesuai dengan nilai k yang telah ditentukan. Pada algoritma ini dibutuhkan centroid atau nilai pusat serta menghitung jarak kedekatan data dengan centroid. Algoritma ini dilakukan secara berulang sampai tidak ada perubahan anggota dalam masing-masing kelompok.
KNN atau K-Nearest Neighbour merupakan salah satu algoritma supervised learning yang mengklasifikasikan atau mengelompokkan data ke dalam beberapa kelompok berdasarkan kemiripan sifat dari data. Algoritma ini hampir mirip dengan algoritma K-Means, yang membedakan adalah pada K-Means melakukan proses clustering sedangkan pada KNN melakukan proses klasifikasi. Terkadang orang menyebut algoritma ini dengan sebutan algoritma malas dikarenakan pada algoritma ini tidak mempelajari cara mengkategorikan data akan tetapi hanya mengingat data yang sudah ada.
Mulai Belajar Menjadi Data Scientist dari Sekarang!
Tahukah kalian bahwa data scientist kini sangat banyak diminati oleh berbagai kalangan. Data scientist merupakan profesi terseksi di abad ini serta gaji dan jenjang karirnya pun cukup menjanjikan. Jadi, Untuk mengetahui lebih lanjut terkait data scientist kita dapat mempelajarinya di DQLab lohh. Caranya sangat mudah, yaitu cukup signup di DQLab dan nikmati momen belajar gratis bersama DQLab dengan mengakses module gratis dari R, Python atau SQL!
Penulis : Latifah Uswatun Khasanah
Editor : Annissa Widya Davita
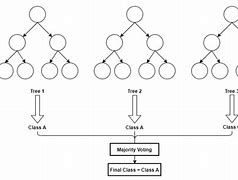
Hierarchical Clustering
Hierarchical Clustering adalah teknik clustering dengan algoritma Machine Learning yang membentuk hirarki atau berdasarkan tingkatan tertentu sehingga menyerupai struktur pohon. Dengan demikian proses pengelompokannya dilakukan secara bertingkat atau bertahap. Biasanya, metode ini digunakan pada data yang jumlahnya tidak terlalu banyak dan jumlah cluster yang akan dibentuk belum diketahui.
Secara prinsip, Hierarchical Clustering ini akan melakukan clustering secara berjenjang berdasarkan kemiripan tiap data. Sehingga pada akhirnya, pada ujung hierarki akan terbentuk cluster-cluster yang karakteristiknya berbeda satu sama lain, dan objek di satu cluster yang sama memiliki kemiripan satu sama lain.
Di dalam metode hirarki, terdapat dua jenis strategi pengelompokan yaitu Agglomerative dan Divisive. Agglomerative Clustering (metode penggabungan) adalah strategi pengelompokan hirarki yang dimulai dengan setiap objek dalam satu cluster yang terpisah kemudian membentuk cluster yang semakin membesar. Jadi, banyaknya cluster awal adalah sama dengan banyaknya objek. Sedangkan Divisive Clustering (metode pembagian) adalah strategi pengelompokan hirarki yang dimulai dari semua objek dikelompokkan menjadi cluster tunggal kemudian dipisah sampai setiap objek berada dalam cluster yang terpisah.
Baca juga : 3 Jenis Algoritma Machine Learning yang Dapat Digunakan di Dunia Perbankan
Support Vector Machine
Support Vector Machine atau biasa dikenal dengan algoritma SVM adalah algoritma machine learning yang digunakan untuk masalah klasifikasi atau regresi. Namun, aplikasi yang paling sering digunakan adalah masalah klasifikasi. Algoritma SVM banyak digunakan untuk mengklasifikasikan dokumen teknis misalnya spam filtering, mengkategorikan artikel berita berdasarkan topik, dan lain sebagainya. Keuntungan algoritma ini adalah cepat, efektif untuk ruang dimensi tinggi, akurasi yang bagus, powerful dan fleksibel, dan dapat digunakan di banyak aplikasi.
Unsupervised Learning
Kita dapat mebayangkan unsupervised learning sebagai usaha cara menemukan variabel-variabel tertentu dari data. Seperti namanya, unsupervised learning machine learning tidak memiliki pengawasan atau panduan dari manusia dalam mempelajari data. Sebaliknya, mesin diharapkan menghasilkan solusi berdasarkan pembelajaran algoritma.
Unsupervised learning dimaksudkan untuk mengeksplorasi data dan menghasilkan output berdasarkan pembelajaran algoritma. Algoritma memberi umpan dari data training tanpa label dan menghasilkan learning output. perhatikan contoh hasil unsupervised learning dengan algoritma K-Means.
Gambar 2. Hasil unsupervised learning dengan K-Means
Hasil di atas adalah algoritma Clustering yang digunakan untuk mengelompokkan data ke dalam sejumlah group. Pemanfaatan lain dari unsupervised learning adalah Dimensionality Reduction yang menyederhanakan data tanpa kehilangan terlalu banyak informasi dari data asli.
Algoritma Klasifikasi pada Machine Learning
Kita telah memahami dasar untuk setiap sistem machine learning dan bagaimana masalah yang berbeda memerlukan algoritma yang berbeda. Secara umum, sebagian besar masalah di industri adalah masalah klasifikasi, sehingga akan berguna bagi kita untuk memahami lebih lanjut tentang algoritma klasifikasi.
Mari kita pahami tujuh algoritma klasifikasi yang paling sering digunakan dan kapan masing-masing algoritma bisa digunakan.
Support Vector Machine (SVM)
SVM adalah algoritma klasifikasi yang cukup populer karena berhasil melampaui beberapa algoritma canggih lainnya pada kasus tertentu, seperti digits recognition. Dalam istilah yang lebih sederhana, SVM adalah pengklasifikasi yang membuat batasan untuk memisahkan kelas-kelas yang berbeda. Data disebut support vektor untuk membantu membuat batasan.
Batasan itu disebut hyperplane atau pembagi. Ini dihitung berdasarkan dataset dan dengan mengukur margin terbaik dengan memindahkan hyperplane. Ketika data berada dalam dimensi yang lebih tinggi atau ketika ada data yang tidak dapat dipisahkan secara linear, kita akan menggunakan Kernel trick untuk menemukan hyperplane.
Perhitungan untuk mengukur hyperplane memang sulit, dan saya menyarankan membaca materi berikut di sini. Berikut adalah representasi gambar SVM.
Gambar 12. Ilustrasi SVM dapat dipisahkan dari hyperplane
Model machine learning adalah algoritma yang dirancang untuk mempelajari data dan membuat output yang memecahkan masalah manusia. Apa itu algoritma klasifikasi dalam machine learning, dan seberapa berguna setiap model dalam menyelesaikan masalah bisnis kita?



